Gico
-
Posts
292 -
Joined
-
Last visited
Gico's Achievements
")
-
After upgrading UD Preclear to 2024.04.23 when starting a preclear it offers to resume or start new one, and what ever I select it goes to "starting" mode and stays in that mode. Uninstalled and reinstalled the plugin and it's the same. Unraid 6.12.6. While installing I got the following message, which corresponds with @Rozella's post. "Checking tmux operation... tmux is not working properly"
-
Same happens with a different HBA: LSI PCI-E card. Is there anyway to limit the available disk size to 22000000000000? I can also try zeroing it on my main machine (the one in my signature). Apr 23 14:23:27 preclear_disk_ZGG46T0A_10952: Zeroing: dd output: 22000449880064 bytes (22 TB, 20 TiB) copied, 98245.7 s, 224 MB/s Apr 23 14:23:27 preclear_disk_ZGG46T0A_10952: dd process hung at 22000451977216, killing ... Apr 23 14:23:27 preclear_disk_ZGG46T0A_10952: Zeroing: zeroing the disk started 2 of 5 retries... Apr 23 14:23:27 preclear_disk_ZGG46T0A_10952: Continuing disk write on byte 22000449880064 Apr 23 14:31:52 preclear_disk_ZGG46T0A_10952: Zeroing: dd output: Apr 23 14:31:52 preclear_disk_ZGG46T0A_10952: dd process hung at 0, killing ... Apr 23 14:31:52 preclear_disk_ZGG46T0A_10952: Zeroing: zeroing the disk started 3 of 5 retries... Apr 23 14:31:52 preclear_disk_ZGG46T0A_10952: Zeroing: emptying the MBR.
-
Yes always stops somewhere after 22000000000000. Disk is attached to an onboard controller and the MB (Supermicro H12SSL-i ) has another one that seems to be identical. I will try with an HBA card.
-
A new 22TB disk, Zeroing is on it's 5th attempt after 4 failed ones. Any reason for that / anything I can do/check? Preclearing only to test the disk. Destined to be a parity disk. Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10486367+0 records out Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 21991505526784 bytes (22 TB, 20 TiB) copied, 100595 s, 219 MB/s Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10487104+0 records in Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10487104+0 records out Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 21993051127808 bytes (22 TB, 20 TiB) copied, 100607 s, 219 MB/s Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10487838+0 records in Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10487838+0 records out Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 21994590437376 bytes (22 TB, 20 TiB) copied, 100619 s, 219 MB/s Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10488577+0 records in Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10488577+0 records out Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 21996140232704 bytes (22 TB, 20 TiB) copied, 100631 s, 219 MB/s Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10489298+0 records in Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10489298+0 records out Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 21997652279296 bytes (22 TB, 20 TiB) copied, 100643 s, 219 MB/s Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10490037+0 records in Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10490037+0 records out Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 21999202074624 bytes (22 TB, 20 TiB) copied, 100655 s, 219 MB/s Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10490768+0 records in Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 10490768+0 records out Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: 22000735092736 bytes (22 TB, 20 TiB) copied, 100667 s, 219 MB/s Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: dd process hung at 22000737189888, killing ... Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Zeroing: zeroing the disk started 4 of 5 retries... Apr 19 20:11:16 preclear_disk_ZGG46T0A_12945: Continuing disk write on byte 22000735092736 Apr 19 20:19:41 preclear_disk_ZGG46T0A_12945: Zeroing: dd output: Apr 19 20:19:41 preclear_disk_ZGG46T0A_12945: dd process hung at 0, killing ... Apr 19 20:19:41 preclear_disk_ZGG46T0A_12945: Zeroing: zeroing the disk started 5 of 5 retries... Apr 19 20:19:41 preclear_disk_ZGG46T0A_12945: Zeroing: emptying the MBR. Apr 20 02:29:32 preclear_disk_ZGG46T0A_12945: Zeroing: progress - 25% zeroed @ 265 MB/s Apr 20 08:34:41 preclear_disk_ZGG46T0A_12945: Zeroing: progress - 50% zeroed @ 234 MB/s Apr 20 15:34:20 preclear_disk_ZGG46T0A_12945: Zeroing: progress - 75% zeroed @ 197 MB/s
-
Admittedly having some OCD ("O" as in Order 😀) and being a control freak, the split level option is welcomed by my kind. Usually I don't rely on it, and I copy my media to disk shares, but in Kodi v20 a new artwork scraper plugin called Artwork Dump was introduced that regularly writes to the media folders, so this option is now important for me. Also in the bad scenario of losing a disk / data (been there), I would rather know what I lost, so prefer it to be alphabetically organized, rather than every time that I need to know if a specific media exists, I'll have to open a spreadsheet.
-
Obviously that was it. Forgot about this restriction 🙂. Many thanks
-
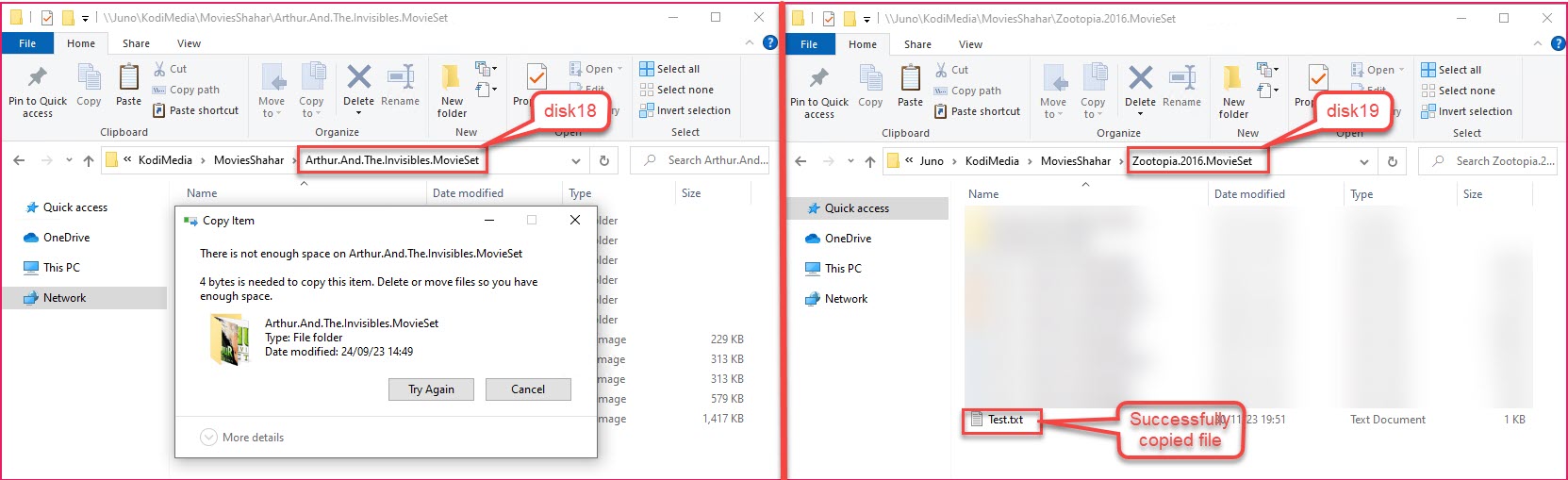
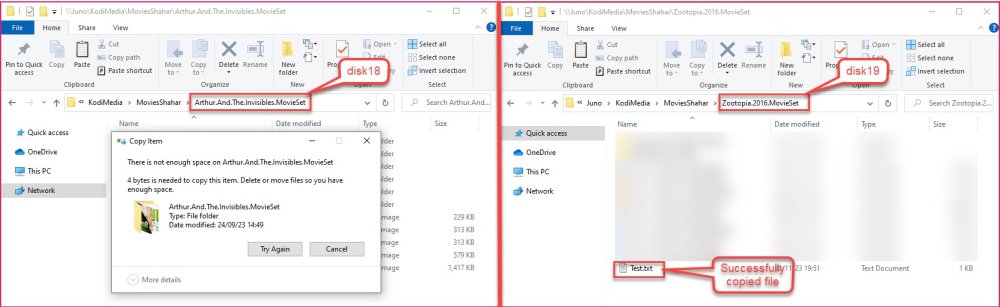
Diagnostics attached. I tried again to copy just now, December 1st 08:20 AM. MoviesShahar A-F subfolders are on disk18, G-Z are on disk19, and exactly starting with G folders is where all copies are failing. This issue occurs also in other folder (i.e. not MoviesShahar) that spans on disk18 and other disks, so definitely seems like disk related. juno-diagnostics-20231201-0824.zip
-
I have a share (KodiMedia) that is spanned across multiple disks. This share is secured and only one user has write privilege to it. This user can write to this share with the exception of disk18: When the write is to disk18 I get a "disk is full" error. The disk has 578GB free. The share has "Manual" for split level and I'm writing to a subfolder, so I know which disk should be written to. When writing to a subfolder on a different disk there is no issue. This happens also when I make the share public. I ran "New Permission" for the share and for the disk and nothing changed. Write to the disk share always ok. Checked the xfs fs in maintenance mode and no issues reported. Any advice?
-
I tested the memory sticks. 8 Passes of 4 sticks passed successfully without any error. 8 Passes of 4 the other 4 sticks (using the same slots as the previous 4) passed successfully without any error. 8 Passes of all the 8 sticks together passed successfully with 1 corrected ECC error. This might indicate that one of the slots being used by sticks 5-8 has an issue, but I doubt it. I don't know if this has nothing to do with the ECC errors, but the CPU fan is adjacent and actually touching one of the sticks. On my initial testing I in stalled the fan next to that stick, so the fan pushed a little the stick horizontally, and when doing the latter tests I installed the stick under the fan, so it might pushed the fan up a little, as seen in the screenshot.

-
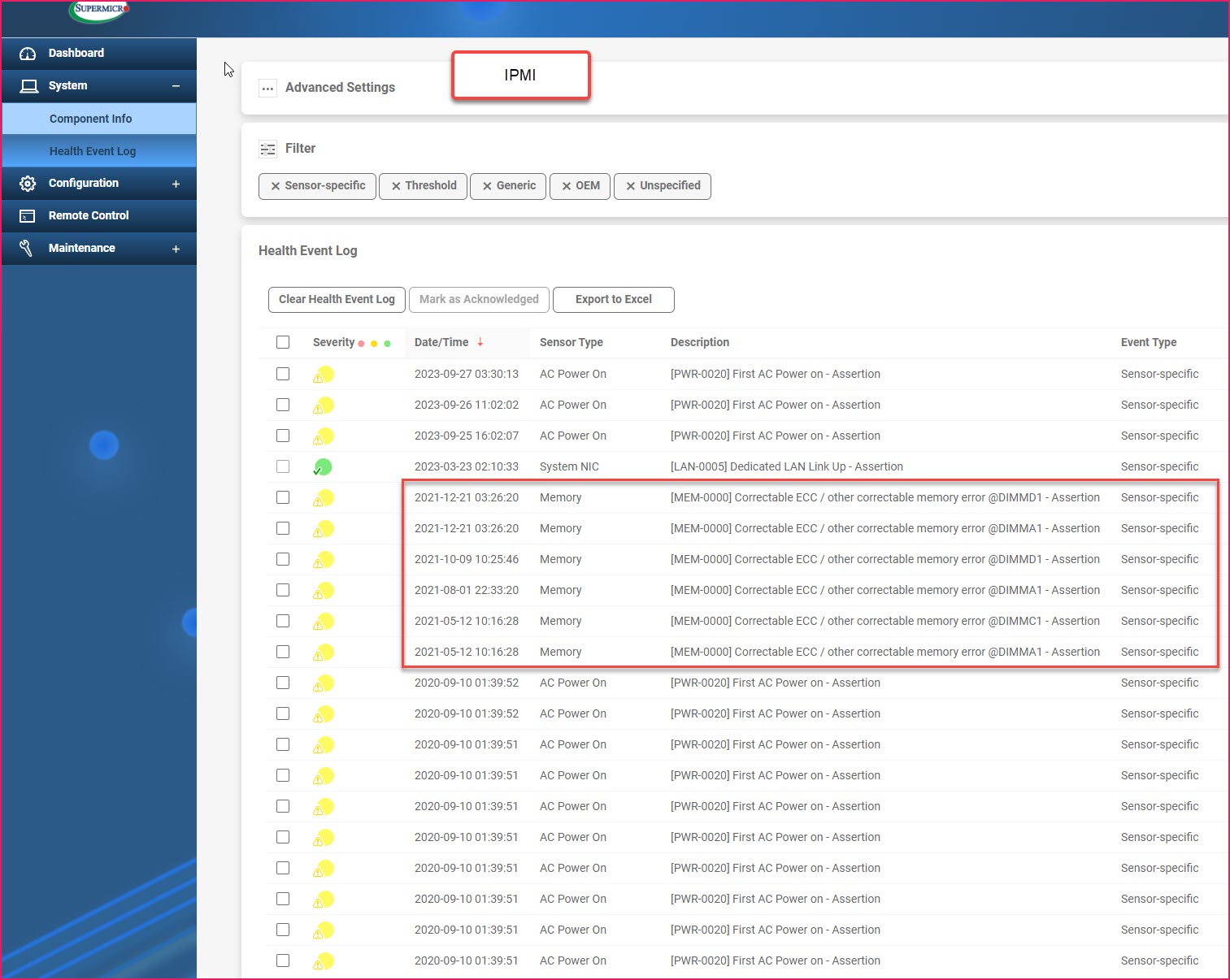
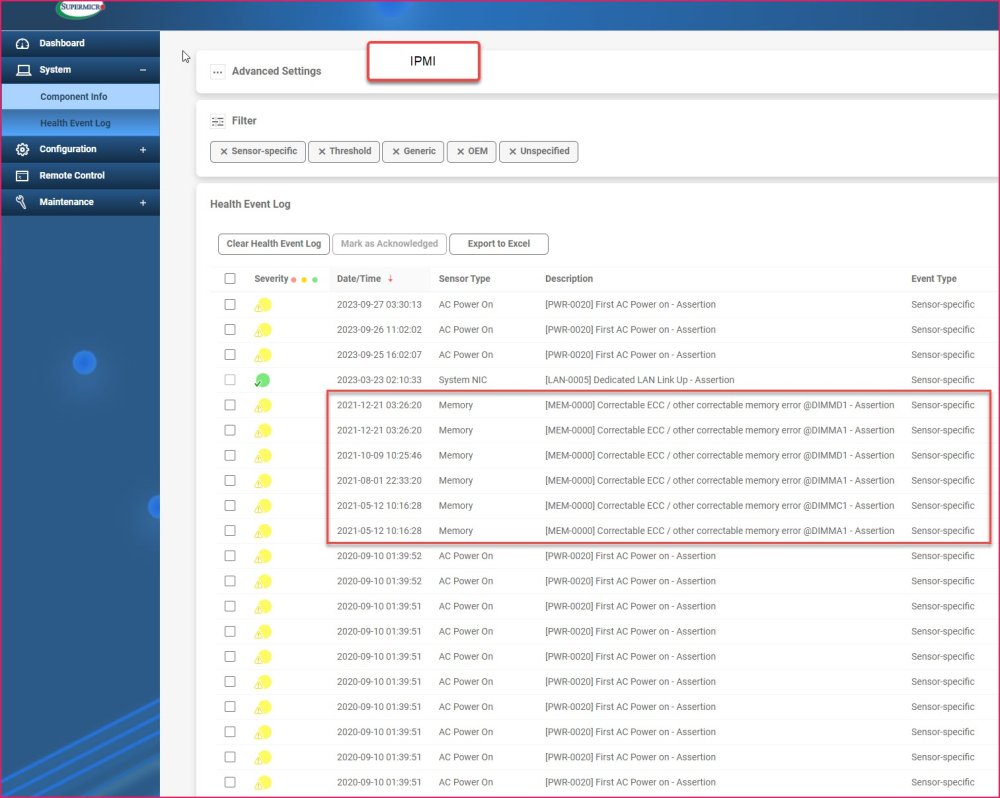
Didn't find anything relevant. The "Health Event Log" in the IPMI has similar errors in 2021. BIOS had only configuration of system event log, not the event log entries. Found "SMBIOS event log" which wasn't relevant.
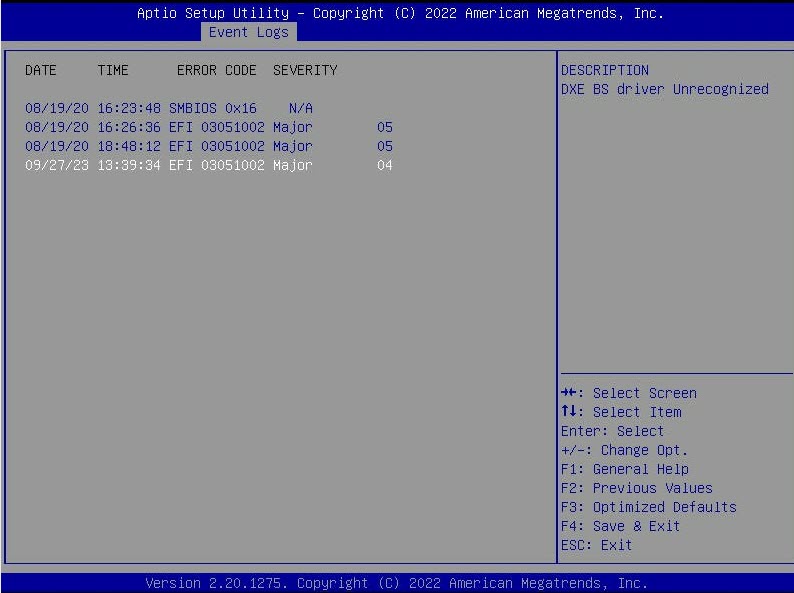
-
Hi. I'm testing the memory of a new server hardware and got these ECC errors this morning after about 60 hours of total interrupted memtest run. Total errors is zero so hardware overcame these issue. I didn't mean to run memtest this long, but had three power failures in my home, and the server is not connected to a UPS, so the memtest restarted and continued to test. One full test pass (~ 20 hours) was completed without any errors / ECC Errors. These errors began this morning, about 15 minutes after the third power failure. All logs (found on the memtest86 USB stick) beside the current one have no errors and no fixed ECC errors. Any recommendation? Should I start looking for a malfunctioned Dimm? Maybe run several passes (only) of these failed tests, this time with a UPS? Each pass would take about 4 hours. The hardware was bought used: MB: Supermicro HL12SSL-I CPU: EPYC 7302 + 4U fan Mem: 8X64GB Samsung PC4-2666V Registered ECC DDR4 PSU: Corsair HX1200i
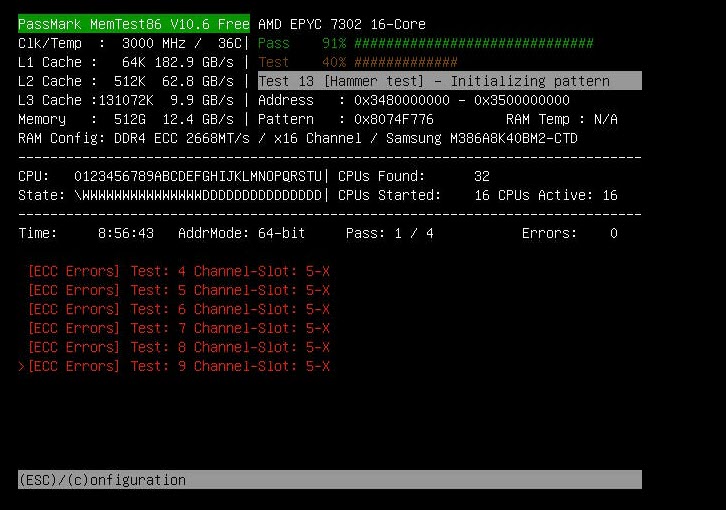
-
[Support] Linuxserver.io - Plex Media Server
Gico replied to linuxserver.io's topic in Docker Containers
I'm having the same issue too and been struggling with it for an hour now: Restart, remove container without/with deleting the image, and still nothing, not even logs written to appdata/plex/Library/Application Support/Plex Media Server/Logs. Edit: Woke up this morning and the server is working ok. -
Just used it and worked like a charm. Thanks! To find source mdX (mine is disk9): lsblk | grep disk9 md9p1 9:9 0 10.9T 0 md /mnt/disk9 I knew that nothing writes to the array disk but tried the -no-remount-readonly switch and for some reason it didn't work and the partition was remounted as read only. ./xfs_undelete -t 2023-08-24..2023-08-25 -r 'video/*' -o /mnt/p2ppool/Temp/ /dev/md9p1 -no-remount-readonly /dev/md9p1 (/dev/md9p1) is currently mounted read-write. Trying to remount read-only. Remount successful. Starting recovery. Recovered file -> /mnt/p2ppool/Temp/2023-08-24-18-13_4297004664.matroska Recovered file -> /mnt/p2ppool/Temp/2023-08-24-18-14_4297004665.matroska Recovered file -> /mnt/p2ppool/Temp/2023-08-24-18-14_4297004666.matroska Recovered file -> /mnt/p2ppool/Temp/2023-08-24-18-14_4297004667.matroska Recovered file -> /mnt/p2ppool/Temp/2023-08-24-18-14_4297004668.matroska Recovered file -> /mnt/p2ppool/Temp/2023-08-24-18-14_4297004669.matroska Done. To remount the partition as read/write: root@Juno:/mnt/p2ppool/Temp/xfs_undelete-12.1# sudo mount -o remount,rw /dev/md9p1
-
Disk Dropped from Array and Emulated Disk Not Accessible
Gico replied to Gico's topic in General Support
Stopped the array, unassigned disk5, started the array, stopped, reassigned disk5, started the array. Parity build began for disk1 & disk5, but I'm quite skeptic whether the base issue was found/solved. -
Disk Dropped from Array and Emulated Disk Not Accessible
Gico replied to Gico's topic in General Support
Diagnostics attached. One of my cache drives had CRC errors. Replaced it's data cable and it's ok now. How can I make disk5 available while rebuild is running? juno-diagnostics-20230809-0003.zip