

nukeman
-
Posts
32 -
Joined
-
Last visited
nukeman's Achievements
")
Noob (1/14)
3
Reputation
-
Thank you for all the help, I got it sorted out. I stopped the docker and vm services. Then I was able to restore the /system directory to its default location on /mnt/cache. That put the previous versions of system\docker\docker.img and system\ibvirt\libvirt.img back in their original locations. Once I started the docker and vm services back up, everything was back to normal.
-
I've been looking at my director structure. There's still folders for all my dockers in /mnt/cache/appdata There's still folders for all my vm's in /mnt/cache/domains Are you saying if I reinstall the dockers it will use the previous settings and not start over from scratch? That's good news.
-
First, I think I did this to myself but I'll try my best to recreate the sequence of events. Last night I was preparing to copy my share data to an external (unassigned) drive for backup. I was reviewing the filesystem and noticed that I had a /system folder on one of my array disks. I thought this was odd because my system share is set for Cache as primary storage and Array as secondary. There is plenty of available space on my Cache so I concluded that the /system folder on the array drive was left over from some previous evolution and wasn't needed. I confirmed that the dates on the files in the array system folder were several months old. Furthermore, there was a system folder on my cache drive with with files that were modified today. Assuming I didn't need it, I moved the array system folder to another location on the array. The destination doesn't use the cache and is excluded from my backups. I then proceed with backing up my share data to the external drive. I let it run all night and while I was at work I got a notification that a parity check had started. That was odd so when I got home I checked the GUI and saw that unassigned drive had an icon next to it saying "reboot" (I use the unassigned devices plugin). I've never seen that before so I paused the parity check, stopped the array and rebooted. After reboot I'm missing all my docker apps and VMs. I copied the /system back where I moved if from and stopped/started the array. Still no luck. I stopped there, and thought I'd reach out for help. I do use Appdata backup and those backups seem to be current. Happy to provide any information that will further help troubleshooting nas-diagnostics-20240220-1813.zip
-
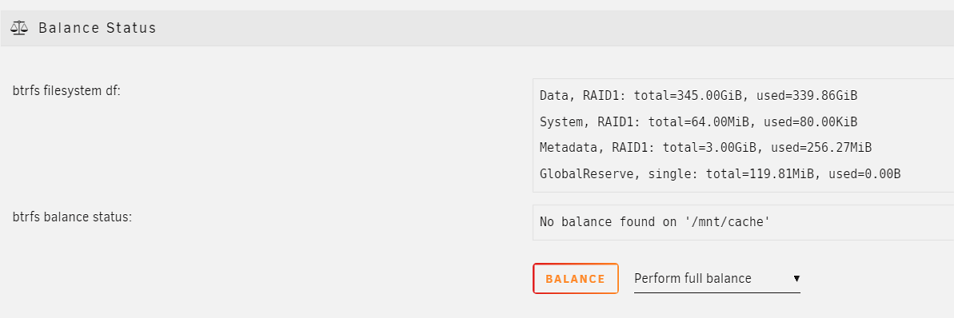
I sent one of the cache pool drives back to Samsung. They sent a new(?) refurbished replacement. I added the replacement drive to the pool and Unraid did a parity check and found no errors. Is that all I need to do prior to RMA'ing the other, original, cache drive. I've never done this procedure before and want to make sure I'm good to remove the other faulty drive. Is "no balance found" relevant?
-
I've finally ran out of onboard SATA ports and I'd like to add a controller card to my system. I'm using a SuperMicro X10SLH-F motherboard and have open "PCI-E 3.0 x8" and "PCI-E 3.0 x8 (in x16)" ports. I've read the recommendation thread and I'm looking for an 8 port controller card. Based on that post, I'm looking for "9207-8i, 9300-8i and newer" for PCI 3.0, since my ports are PCI 3.0, right? Does this seem like a reasonable option? IBM branded, us seller with good feedback, breakout cables included, $60. Or, this one is LSI branded for $20 more. This is an x10 board from 2015. I want to make sure I utilize the full ability of the hardware without buying something so new it's not compatible. Any other recommendations?
-
ok, 45TBs sounded like a lot, but I guess I am moving large media files around frequently. Currently I have my downloads folder using the cache, perhaps it would make sense to not do so. I don't really care about fast writes from downloads. Regardless, I'm going to RMA the drives, one at a time, to keep the server up as much as possible. Plan is to: Remove one of the drives from the pool and return it When I get the replacement drive I'll put it into the pool and let BTRFS rebuild it Then I'll take the other old drive out of the pool and return it finally, I'll put the second replacement drive into the pool Or, should I do this procedure instead? This post says there's trouble rebuilding the pool in 6.9.2? But then, there's a workaround?
-
Are there any reports of excessive writing to cache drives or cache pools? My cache hosts 4-5 VMs and "normal" dockers (Radarr, Sonarr, etc). Both of these drives were introduced into my system when I initially created the cache pool. Prior to that I was just using one (smaller) ssd for cache and docker/vm hosting.
-
Well, I'm going to need some help translating the Wear_Leveling_Count. You're saying I've written 45TB to the drive?!?!? I don't understand how that could happen. Also, I'm not excited to read that report of other 870 EXOs failing...
-
The drives have 671GB free so they're 33% full. Here's the smart reports. 2947T SMART Report.txt 2900M SMART Report.txt
-
Recently I received a warning about some Reallocated Sectors on one of the SSDs in my cache pool. The other day I was doing some heavy copying with the cache and received a similar warning on the other drive in the pool. I've searched the forums and this seems to be either "watch it to see if it gets worse" or "critical fix it now" problem. I went back and found some old diagnostics and two months ago both drives had Reallocated_Sector_Ct=0 in their SMART reports. Now one drive has Reallocated_Sector_Ct=3 and Reallocated_Sector_Ct=7. Both of these drives are 1TB Samsung Evo 870's that were purchased in February of 2021. I'm not excited about the prospect of swapping out the drives as they contain several critical VMs for my home business as well as Unraid's Cache. That being said, I'm also not excited about both drives in my cache pool failing at the same time. Assuming these warnings are something I should take care of I started the RMA process with Samsung. I did get an RMA issued but they won't send out a replacement drive until I send the old one in for evaluation. Before I start down that road though, I wanted to get some opinions on what my next steps should be. Is this a warning that warrants replacing both drives? If so, how should I go about doing it? I thought Samsung SSDs were generally well regarded, maybe I just got unlucky? BTW - I'm happy to post the SMART reports but I'm wondering if there's any sensitive information I should remove? Like should I remove the serial numbers in the report prior to posting?
-
First I exported my video library to separate files by following these instructions. Then I setup MySQL like normal and imported the library from the exported nfo files. Finally, once I validated the import was successful, I deleted all the nfo files. Pay attention to the importwatchedstate and importresumepoint options when importing.
-
No, not with MariaDB. I installed a MySQL docker and everything is back to working like it should.
-
I'm experiencing a weird issue with kodi and a shared mariadb . Right now my setup contains a windows laptop, android tablet, shieldtv, and chromebook that all share the same video and music database. I think I've isolated the behavior to the following: if I open kodi on the windows laptop, I can no longer open kodi on the android devices. If I reset the mariadb docker container, android starts working again. I've been running a shared database for years without seeing this issue. It seems to be similar to what's mentioned here but there's no solution. I don't know if this has to do with the issues from that started popping up here around in August. These seemed to be related with the update from ubuntu to alpine. The fix was to downgrade mariadb then upgrade to latest. If this is the issue referenced above, would someone summarize the steps required to fix it? The steps are mentioned in this thread but it's kind of scattered and hard to follow. The relevant section of the chromebook's kodi log after the windows laptop launched kodi: 2021-11-15 19:07:18.664 T:5323 INFO <general>: MYSQL: Connected to version 10.5.13-MariaDB-log 2021-11-15 19:07:18.761 T:5323 ERROR <general>: SQL: [music-adults82] An unknown error occurred Query: SELECT idVersion FROM version 2021-11-15 19:07:18.763 T:5323 ERROR <general>: Process error processing job I realize "An unknown error occurred" isn't very helpful and I'd be happy to post more relevant logs from kodi and mariadb once we confirm what the problem is. Anybody else experience this?
-
Windows 10 VM poor performance, 100% CPU after 6.9 upgrade
nukeman replied to nukeman's topic in VM Engine (KVM)
There's been lots of responses since I started this post and I thought I'd provide the group an update. After changing my CPU Scaling Governor to "On Demand" the stability of my system improved dramatically. I could install the Ubuntu Desktop VM and its performance is acceptable. Also, the CPU use in the dashboard isn't spiking like it was previously. Sounds like the CPU Scaling Governor setting hasn't fixed this for everyone, but it seems to be working for me. -
Windows 10 VM poor performance, 100% CPU after 6.9 upgrade
nukeman replied to nukeman's topic in VM Engine (KVM)
Um, so this is embarrassing. I have "Tips and Tweaks" installed but I don't remember ever changing any settings listed there. I changed "CPU Scaling Governor" to "On Demand" as you suggested. I also changed "Enable Intel Turbo/AMD Performance Boost" to "Yes". I rebooted the server for good measure. Performance inside the VMs seems much better and CPU usage on the dashboard has gone down as well. I'll keep an eye on this for and see if it remains stable. Thanks to @stor44 for the suggestion, hopefully it helps others too.

