shat
-
Posts
276 -
Joined
-
Last visited
shat's Achievements
")
Contributor (5/14)
5
Reputation
-
Anyone have any suggestions? I just upgraded to Windows 10 and had some hopes that it would resolve itself with it; it did not.
-
Additional files Music.cfg syslog.txt vars.txt ps.txt
-
At some point in my progress of upgrading to v6; I have seemingly lost the ability to access my user shares or see my unRAID v6.1.6 server on my network from a Windows 7 workstation. I am able to access the shares via AFP and SMB on my macbook. I have: - verified NFS, AFP, SMB are enabled - verified no iptables rules are blocking 138, 139, 445 (unRAID doesn't appear to use one of t hose 3 ports for SMB) - verified all the shares are exported in said ways that I need to access - ensured my workstation and unraid are within the same workgroup and that master is set to yes on unRAID. - disabled any/all network firewall policies on my windows 7 machine additional steps I tried without success in the end result of access the shares in any way: - installed Umich's NFSD4.1; has its own issue of complaining about AD (I'm not using a directory environment on my home network) - modified Windows 7 Profession to Enterprise registry settings so I could attempt to install NFS client tools via Windows Components as it is unavailable on Professional; but is available for Enterprise versions (didn't work) I can reach the server via browser http://10.0.10.50 I can ping the server without any issues Running out of ideas. I am attaching a bunch of data, not sure if it is helpful; but here goes. disk.cfg network.cfg ident.cfg smb-extra.conf
-
The drive is still green, one of them showing the error doesn't have any errors in the report itself, so I am confused a bit.
-
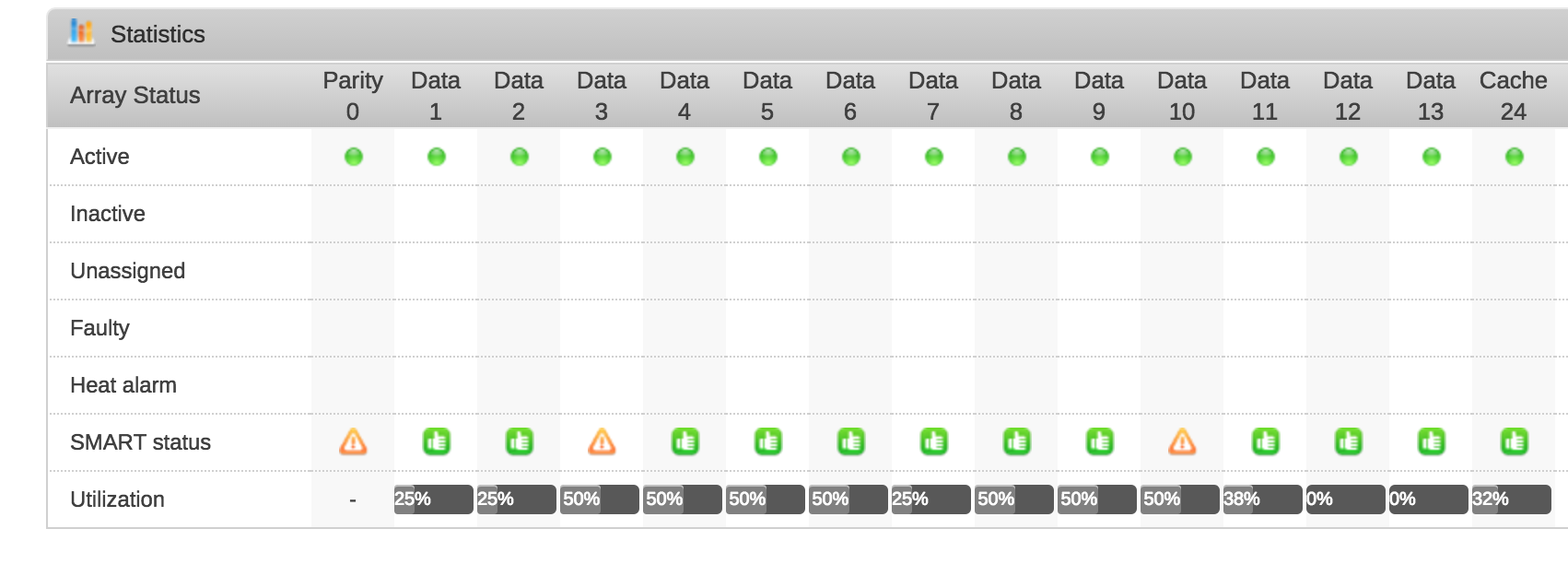
I finally got around to upgrading to 6.1.6 this evening. I performed a parity check before the upgrade and proceeded. The upgrade seems to have completed successfully as I have rebooted and run new perms without any issue.. However, I noticed I have a few drives with some smart issues / errors occurring. I've attached the SMART reports from the two drives, the parity drive is showing errors; unrelated to SMART apparently, but attached as well. One of the drives has 1012 errors. Parity 0: Reallocated sector count 5 Data 3: Reported uncorrect 1012 Data 10: Current pending sector 1, Offline uncorrectable 3 Attachments are named per drive. Suggestions? I was looking to begin using unBALANCE perhaps to begin converting to BTRFS (prefer) or XFS .. I really want to mount up a few 1+ TB ssds for cache .. been a while since I posted, hello to all btw data10_smart.txt parity_smart.txt data3_smart.txt
-
Bump for unRAID love?
-
Fellow unRAID(ers)! It's been a long, long time since I've posted on the forums and it seems that unRAID has made some seriously bad ass progress on development. I've been keeping an eye on it, but haven't done anything with my existing unRAID which is on 5.0.1-RC1... I rebooted it for the first time in 214 days today and it seems that emhttp refuses to start despite my best efforts at troubleshooting it. It also has become apparent that I should likely begin the process of upgrading to a new version. I have a few questions: 1) Is upgrading from 5.0.1-RC1 to a more 'up to date' version of 6.X feasible and painless? I know in the past upgrading versions has lead to the array become unstable or unusable for many people, so I am curious if anyone else has performed the upgrade (surely there is) and how it went and anything I should be aware of first? 2) Anyone know if Influencer's plugins work on 6.x? 3) It seems there are numerous virtualization options available for the 6.x branch of unRAID which is great. My "tower" is a Xeon 1230v2 with 32gb of memory, so being able to use it for more than just unraid would be nice, but will likely still be unraid related, for example offloading PMS to its own VM using 4 cores instead of all.. same for sab, etc. So, enlighten me if you will. Is the process of upgrading still as straight forward as before or has it changed? I prefer KVM over Xen these days, but anyone have opinions as to which is running 'better' on 6.x?
-
I have had this very same issue and it turned out to be because I was transcoding for audio. If your stereo, soundbar or television doesn't support the audio codec being received by roku via Plex it gets transcoded. Example, my Vizio 60" TV does not support DTS audio, so despite the fact that it is optical cable from TV to sound bar, which does support it, causes plex to transcode it. There is a log file in Plex you can tail and grep for the detail of transcoding taking place. A "1" means real time direct stream and anything slower is transcoded. I would dig on plex forums as well. If you're a plex pass member, the gurus there are always helpful. Just like us with unraid. Sent from my iPhone using Tapatalk
-
[FS] 4TB Western Digital Red Hard Drives (WD40EFRX)
shat replied to tyrindor's topic in Buy, Sell, Trade
Anyone ordered and received? Sent from my iPhone using Tapatalk -
Nice man. Glad you got it tidied up. Loving my little Lian Li mini-itx rigs. Have 4 of them running now. No specific reason why other than to store stuff, heh.
-
Garycase: what's the update on this project? Sent from my iPhone using Tapatalk
-
"SimpleFeatures" - WebServer Plugin [SUPPORT]
shat replied to speeding_ant's topic in User Customizations
Trying to help a friend with his unraid, he has same issue with libssl.so.0 Everything worked fine for a day, he shut it down, took it to his house, turned on and nothing. You can telnet, ping, etc, but plugins are not getting installed. -
I've noticed my server running a little slower than normal these last few days, but drives are all passing SMART tests, parity checks fine and the overall hardware seems to be in good health. Noticed these errors in my log file this evening, not sure how long they have been showing up as I just checked: tail -n 40 -f /var/log/syslog Dec 2 19:53:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 19:53:01 Hoard kernel: crond[25978]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 19:54:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 19:54:01 Hoard kernel: crond[25992]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 19:55:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 19:55:01 Hoard kernel: crond[26006]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 19:56:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 19:56:01 Hoard kernel: crond[26025]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 19:57:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 19:57:01 Hoard kernel: crond[26038]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 19:58:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 19:58:01 Hoard kernel: crond[26054]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 19:59:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 19:59:01 Hoard kernel: crond[26067]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:00:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:00:01 Hoard kernel: crond[26083]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:01:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:01:01 Hoard kernel: crond[26099]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:02:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:02:01 Hoard kernel: crond[26112]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:03:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:03:01 Hoard kernel: crond[26124]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:04:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:04:01 Hoard kernel: crond[26136]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:05:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:05:01 Hoard kernel: crond[26150]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:06:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:06:01 Hoard kernel: crond[26166]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:07:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:07:01 Hoard kernel: crond[26182]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:08:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:08:01 Hoard kernel: crond[26194]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:09:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:09:01 Hoard kernel: crond[26229]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:09:07 Hoard in.telnetd[26230]: connect from 10.0.10.100 (10.0.10.100) Dec 2 20:09:09 Hoard login[26231]: ROOT LOGIN on '/dev/pts/0' from '10.0.10.100' Dec 2 20:10:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:10:01 Hoard kernel: crond[26740]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] Dec 2 20:11:01 Hoard crond[1234]: exit status 1 from user root /usr/lib/sa/sa1 2 1 & >/dev/null Dec 2 20:11:01 Hoard kernel: crond[27635]: segfault at 4001e51c ip 4001e51c sp bfdc0b98 error 15 in ld-2.11.1.so[4001e000+1000] [/cpde] [b]unRAID 5.0.1-rc1[/b] on Intel i5 with 16GB memory (only 8gb is usable I think..)
-
I can align with gary and tyrindor. I have cleared a total of 55 WD red drives, all 3TB, largest bulk was 20 drives. Of the batch of 20, one failed during clear. Got a new one in and no issues. Typically I don't like WD, especially because of the failure rates I have experienced with greens, but the reds are quite nice. Sent from my HTC One using Tapatalk 4
-
[FS] MSI890FXA-GD70 + AMD SEMPRON 140 2.7GHz $100 + $22 shipping
shat replied to shat's topic in Buy, Sell, Trade
I am currently away until sometime after 10/07. Once I return home I will begin processing new requests. Thanks for patience.